HarnessEval: Khi Coding Agent Thất Bại, Lỗi Tại AI Hay Hạ Tầng?
Vấn đề: Không ai biết tại sao Coding Agent thất bại
Năm 2026, coding agent đã trở thành công cụ không thể thiếu. Claude Code, Cursor, SWE-Agent — tất cả đều hứa hẹn “giải quyết bug tự động.” Nhưng khi agent thất bại, một câu hỏi quan trọng luôn bị bỏ ngỏ:
Thất bại vì LLM không đủ giỏi? Hay vì hạ tầng (harness) xung quanh nó thiếu sót?
Tôi đã phân tích 49 bài nghiên cứu từ 2023 đến 2026 và phát hiện: không một công trình nào đánh giá bản thân harness một cách hệ thống. Tất cả 32 bài về evaluation đều chỉ đo output cuối cùng — “agent giải được bao nhiêu task?” — mà không hề quan tâm đến việc thành phần nào của hệ thống đóng góp vào kết quả đó.
Đó là lý do tôi xây dựng HarnessEval.
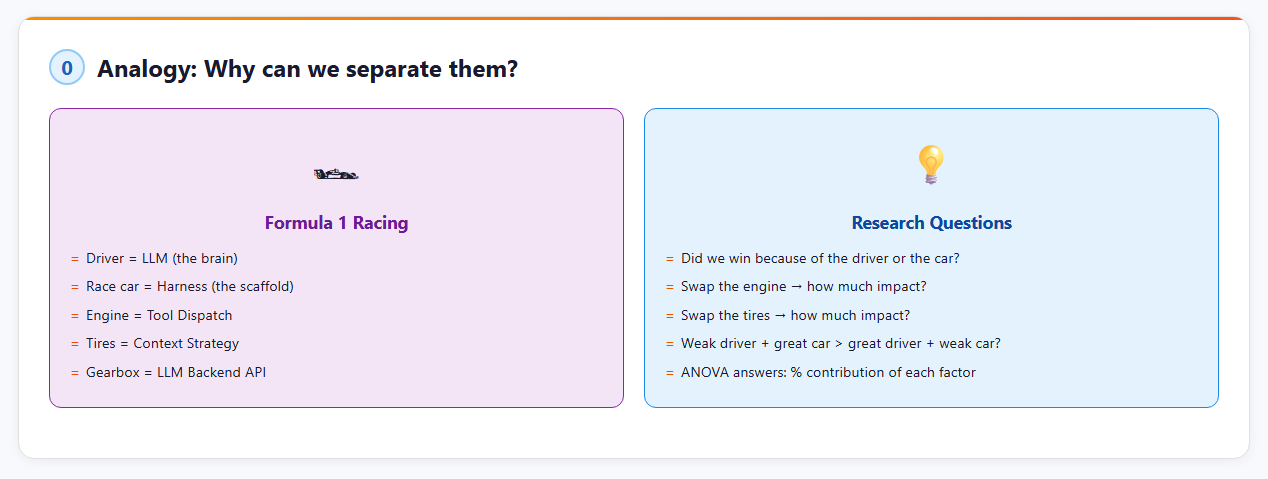
HarnessEval là gì?
HarnessEval là framework đánh giá hạ tầng coding agent đầu tiên, cho phép:
- Đo lường chất lượng từng thành phần của harness (tool system, context management, backend)
- Tách rời đóng góp của harness vs. LLM cơ sở bằng ANOVA 2 chiều
- So sánh harness trên các chiều chất lượng thống nhất
Nói đơn giản: nếu coding agent là xe đua F1, thì LLM là tay đua, còn harness là chiếc xe. HarnessEval trả lời câu hỏi: “Thắng nhờ tay đua hay nhờ xe?”
Research Gap: Tại sao chưa ai làm?
Phân tích gap từ 49 papers cho thấy một bức tranh rõ ràng:
| Khía cạnh | Đã có | Chưa có |
|---|---|---|
| Đo output của agent | SWE-bench, SWE-Compass, AgentBoard | — |
| Đo tool accuracy riêng lẻ | ToolLLM, AnyTool, Gorilla | Đo tool trong harness coding |
| Đo memory riêng lẻ | Mem0, A-MEM (trên chatbot) | Đo memory trong harness coding |
| Mô tả harness design | OpenDev, AutoHarness | Đo lường harness quality |
| So sánh cross-backend | — | Hoàn toàn chưa ai làm |
| Tách harness vs LLM | — | Hoàn toàn chưa ai làm |
Ba lý do chính khiến gap này tồn tại:
-
Vai trò khác nhau: Các nhóm phát triển harness (Princeton — SWE-Agent, Anthropic — Claude Code) là developers, không phải evaluators. Giống như hãng xe sản xuất xe nhưng tổ chức khác (Euro NCAP) đánh giá an toàn.
-
Lĩnh vực phát triển quá nhanh: Từ 2023-2026, số lượng coding agent tăng từ vài hệ thống lên hàng chục. Chưa ai dừng lại để meta-evaluate.
-
Bằng chứng gián tiếp: Lou et al. (2026) đã so sánh harness trên game tasks; Robeyns et al. (2025) tự cải thiện harness nhưng không đo từng component — cho thấy nhu cầu tồn tại nhưng chưa được formalize.
Kiến trúc: Mô hình 5 Lớp Harness
Dựa trên phân tích tài liệu, tôi đề xuất mô hình 5 lớp cho coding agent harness:
┌────────────────────────────────────┐
│ L5: Orchestration (agent loop) │ ← Ngoài phạm vi v2
├────────────────────────────────────┤
│ L4: Safety & Permission │ ← Ngoài phạm vi v2
├────────────────────────────────────┤
│ L3: Context & Memory Management │ ← ĐÁNH GIÁ (D2)
├────────────────────────────────────┤
│ L2: Tool System │ ← ĐÁNH GIÁ (D1)
├────────────────────────────────────┤
│ L1: Model Backend │ ← ĐÁNH GIÁ (D3)
└────────────────────────────────────┘Nghiên cứu tập trung vào 3 lớp dưới (L1-L3). L4-L5 để cho future work.
Vấn đề: Monolithic Harness
Hầu hết harness hiện tại là monolithic — tất cả components gắn chặt với nhau bằng direct function calls. Không thể thay đổi 1 component mà giữ nguyên 2 component còn lại.

Giải pháp: Modular Harness với Strategy Pattern
HarnessEval fork SWE-Agent và refactor thành modular harness, sử dụng:
- Interface/ABC: Định nghĩa “contract” mỗi layer phải tuân thủ
- Strategy Pattern: Nhiều implementations cho cùng interface
- Dependency Injection: Tạo object từ config, không hard-code
- Factory Pattern: Đọc YAML config và tạo đúng combination

Taxonomy 3 Chiều Đánh Giá Harness
HarnessEval đề xuất 3 chiều với tổng cộng 7 metrics:
D1. Tool Dispatch Efficiency
| Metric | Định nghĩa | Cách đo |
|---|---|---|
| M1.1 Correct Tool Selection Rate | % tool calls chọn tool phù hợp | 2 annotators gán nhãn “acceptable/not” cho 500 tool calls |
| M1.2 Redundant Call Rate | % tool calls mà kết quả không được sử dụng trong 3 bước tiếp theo | Log analysis tự động |
| M1.3 Tool Utilization Breadth | Số tool types được sử dụng / tổng số tools khả dụng | Log analysis tự động |
D2. Context Utilization
| Metric | Định nghĩa | Cách đo |
|---|---|---|
| M2.1 Info Retention Score | Cosine similarity giữa full-context và compacted-context response | BERTScore giữa 2 outputs |
| M2.2 Effective Token Ratio | % tokens trong context có liên quan đến task hiện tại | LLM classifier + human validation |
D3. Backend Portability
| Metric | Định nghĩa | Cách đo |
|---|---|---|
| M3.1 Cross-Backend Std Dev | Standard deviation của resolve rate qua 3 backends | Tính trực tiếp |
| M3.2 Min/Max Ratio | min(RR) / max(RR) qua các backends | Giá trị cao = portable |
Thiết Kế Thực Nghiệm: 27 Conditions
Ablation study là phương pháp chuẩn trong ML: loại bỏ/thay đổi từng component để đo đóng góp. HarnessEval áp dụng full factorial design với 3 factors:
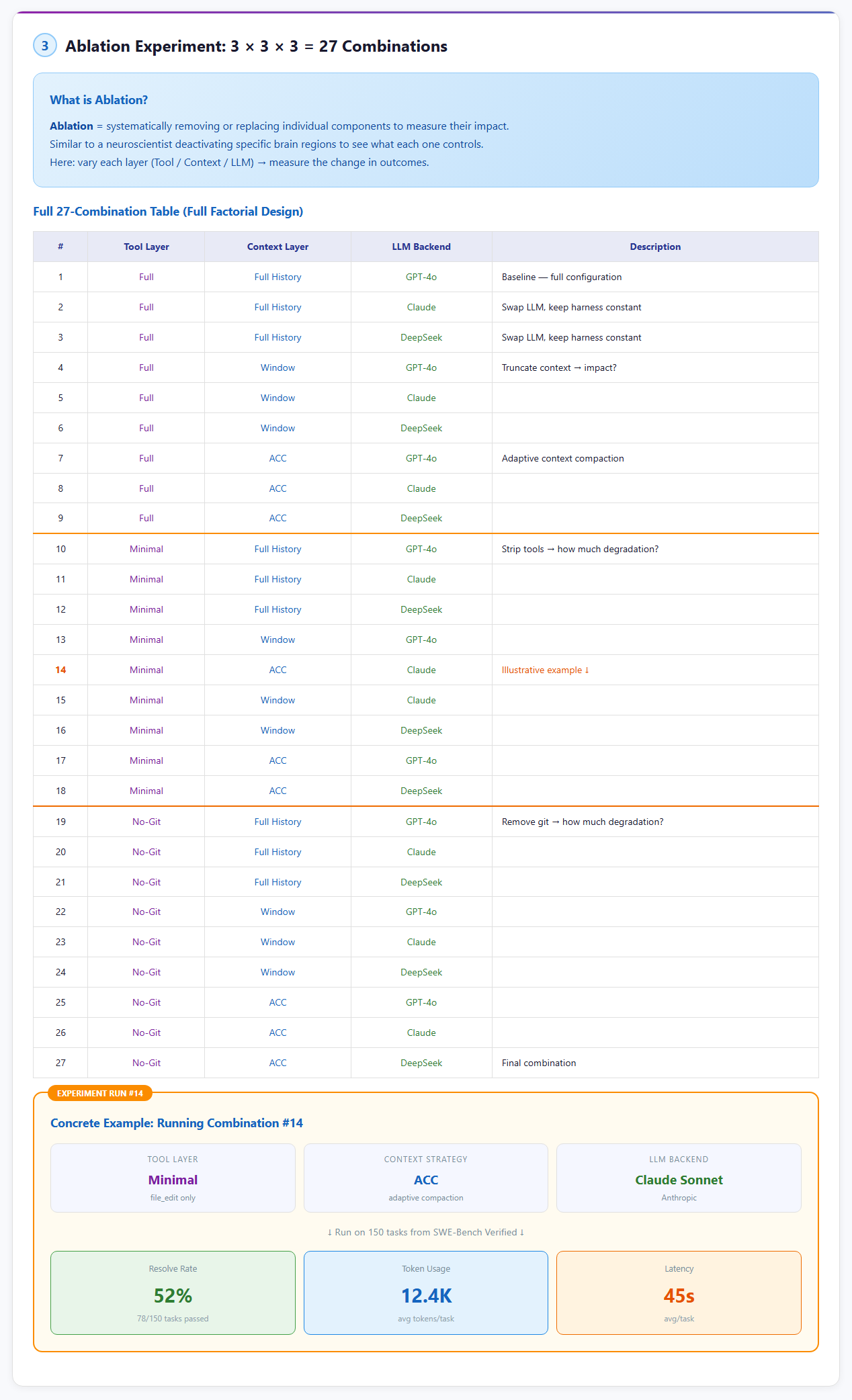
3 Factors
| Factor | Levels | Chi tiết |
|---|---|---|
| Tool Config | 3 | Full (12 tools) / Medium (8 tools) / Minimal (5 tools) |
| Context Strategy | 3 | Full History / Sliding Window (50K tokens) / Summary-based (2K tokens) |
| LLM Backend | 3 | Claude Sonnet 4 / GPT-4o / DeepSeek-V3 |
Tổng: 27 conditions (3 x 3 x 3)
Chiến lược chạy thực nghiệm
- 10 conditions quan trọng nhất: Chạy 3 lần (report mean +/- std)
- 17 conditions còn lại: Chạy 1 lần
- Tổng evaluations: (10 x 3 + 17 x 1) x 150 tasks = 7,050 evaluations
- Dataset: 150 tasks từ SWE-bench Verified (Python)
- Chi phí ước tính: $2,500 - $3,100
Pilot Study trước Full Experiment
Trước khi cam kết chạy hết, pilot study gồm:
- 5 conditions x 20 tasks x 2 runs = 200 evaluations
- Chi phí: ~$80
- Mục đích: validate metrics, ước tính chi phí, debug pipeline
Phân Tích Thống Kê: ANOVA 2 Chiều
Đây là đóng góp lý thuyết chính — formalize cách tách rời harness quality khỏi LLM quality.
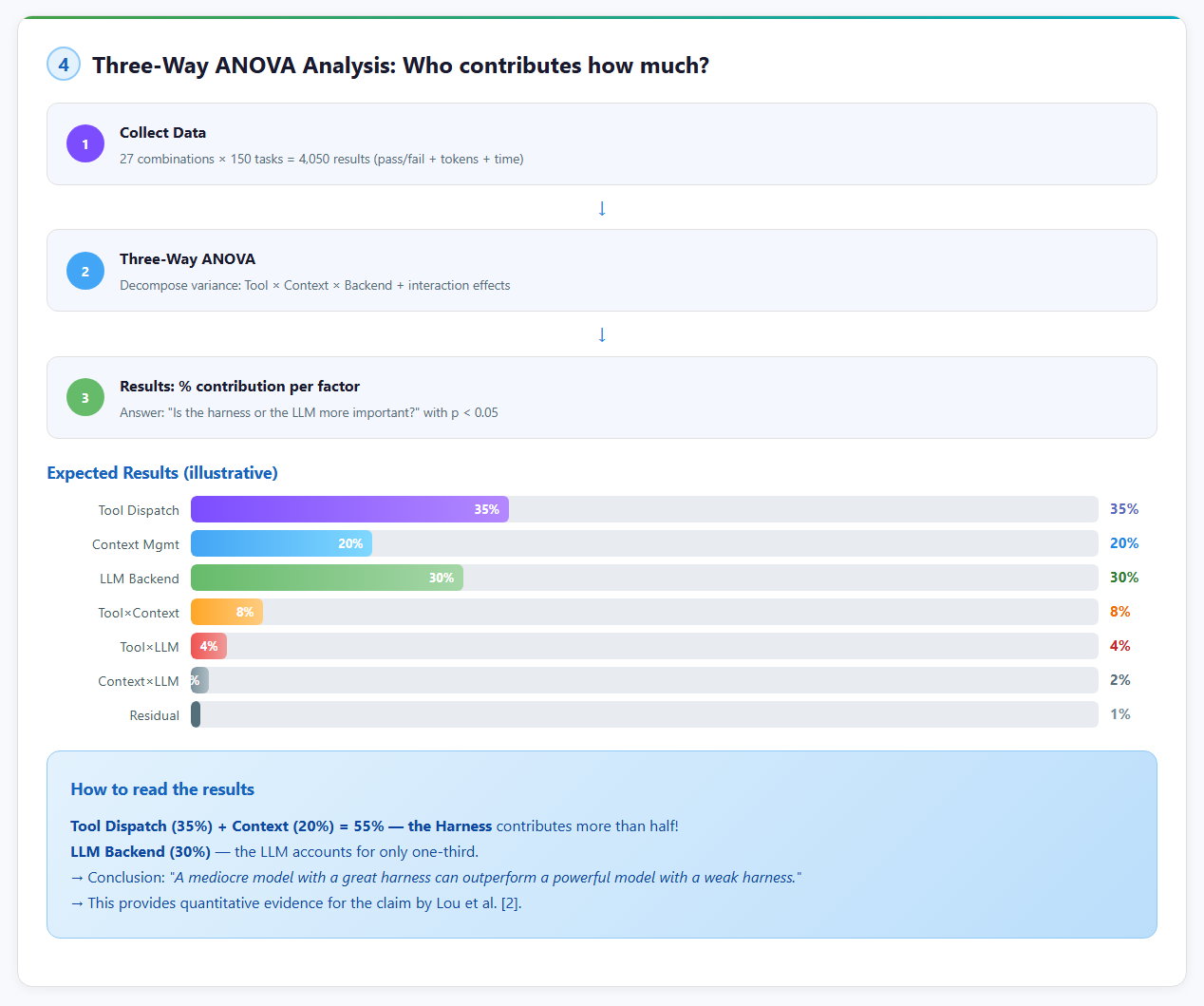
Mô hình ANOVA
Tổng variance = Variance(Harness) + Variance(LLM) + Variance(Harness x LLM) + Error
Nếu Variance(Harness) có ý nghĩa thống kê → harness CÓ ẢNH HƯỞNG độc lập
Nếu Variance(Harness x LLM) có ý nghĩa → có INTERACTION
η² (eta-squared) cho biết % variance được giải thích bởi mỗi factor4 Giả Thuyết Nghiên Cứu
| ID | Giả thuyết | Tiêu chí |
|---|---|---|
| H1 | Tool system có effect size lớn nhất | Cohen’s d > 0.5 |
| H2 | Context management có effect size trung bình | Cohen’s d 0.3-0.5 |
| H3 | Harness giải thích >= 20% variance | eta-squared >= 0.20 |
| H4 | Harness tốt giảm gap giữa các backends | Interaction effect có ý nghĩa |
Dù thành công hay bác bỏ giả thuyết, đều là đóng góp khoa học.
HarnessEval Dashboard — Streamlit UI
Toàn bộ pipeline được quản lý qua Streamlit Dashboard với 5 tab:
Tab 1: Config Builder
Chọn condition bằng 3 radio selectors, xem YAML config, và chạy experiment trực tiếp từ UI.
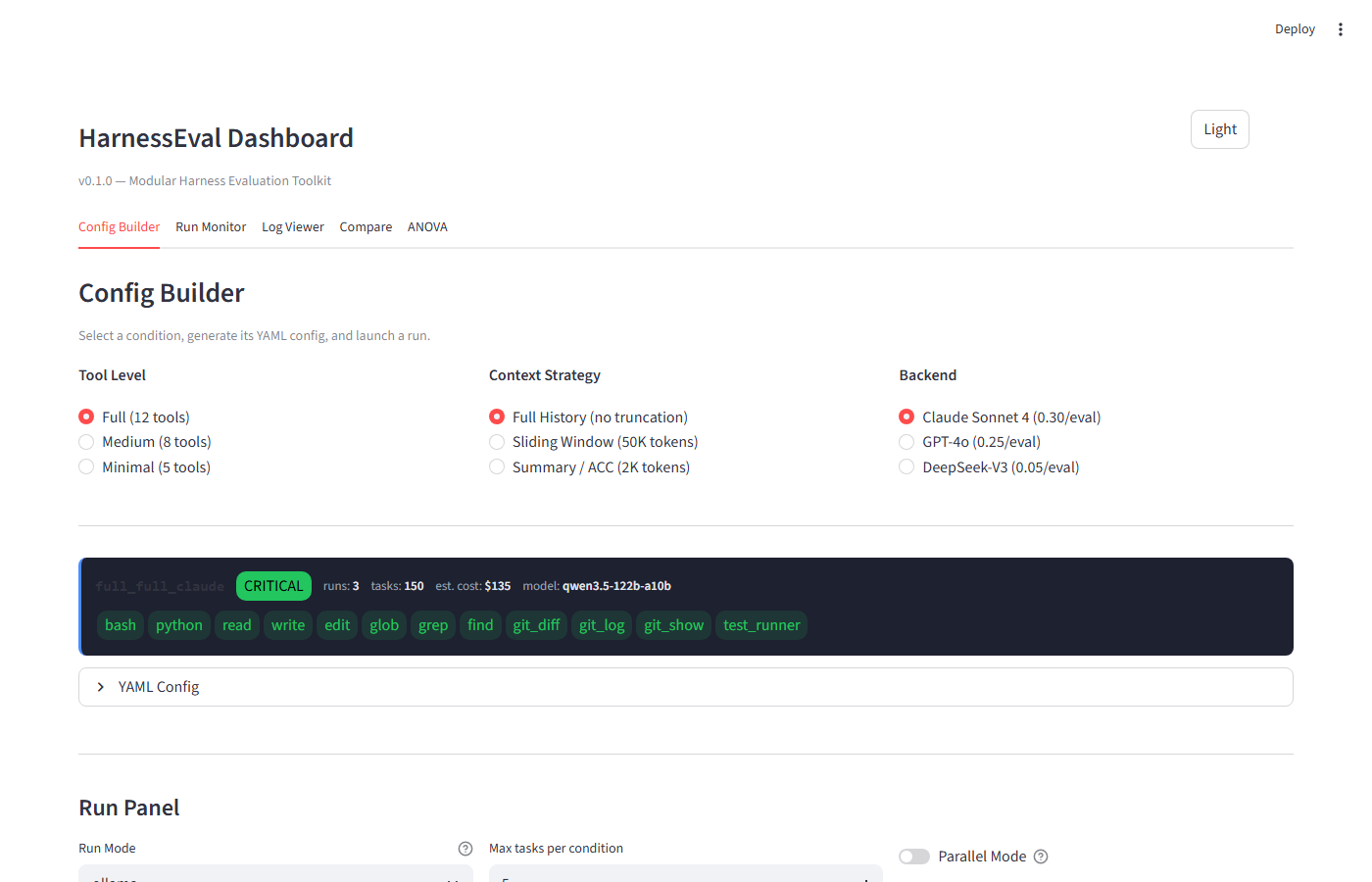
Dashboard hiển thị chip comparison cho tools — tools màu xanh là active, tools bị gạch ngang là bị loại bỏ trong config hiện tại. Hỗ trợ 3 run modes:
- Dry-run: Tạo synthetic data để test pipeline
- Ollama: Chạy với LLM local (miễn phí)
- Real: Chạy SWE-Agent thật với API keys
Tab 2: Run Monitor
Theo dõi tiến trình chạy experiment real-time, với per-condition status table.
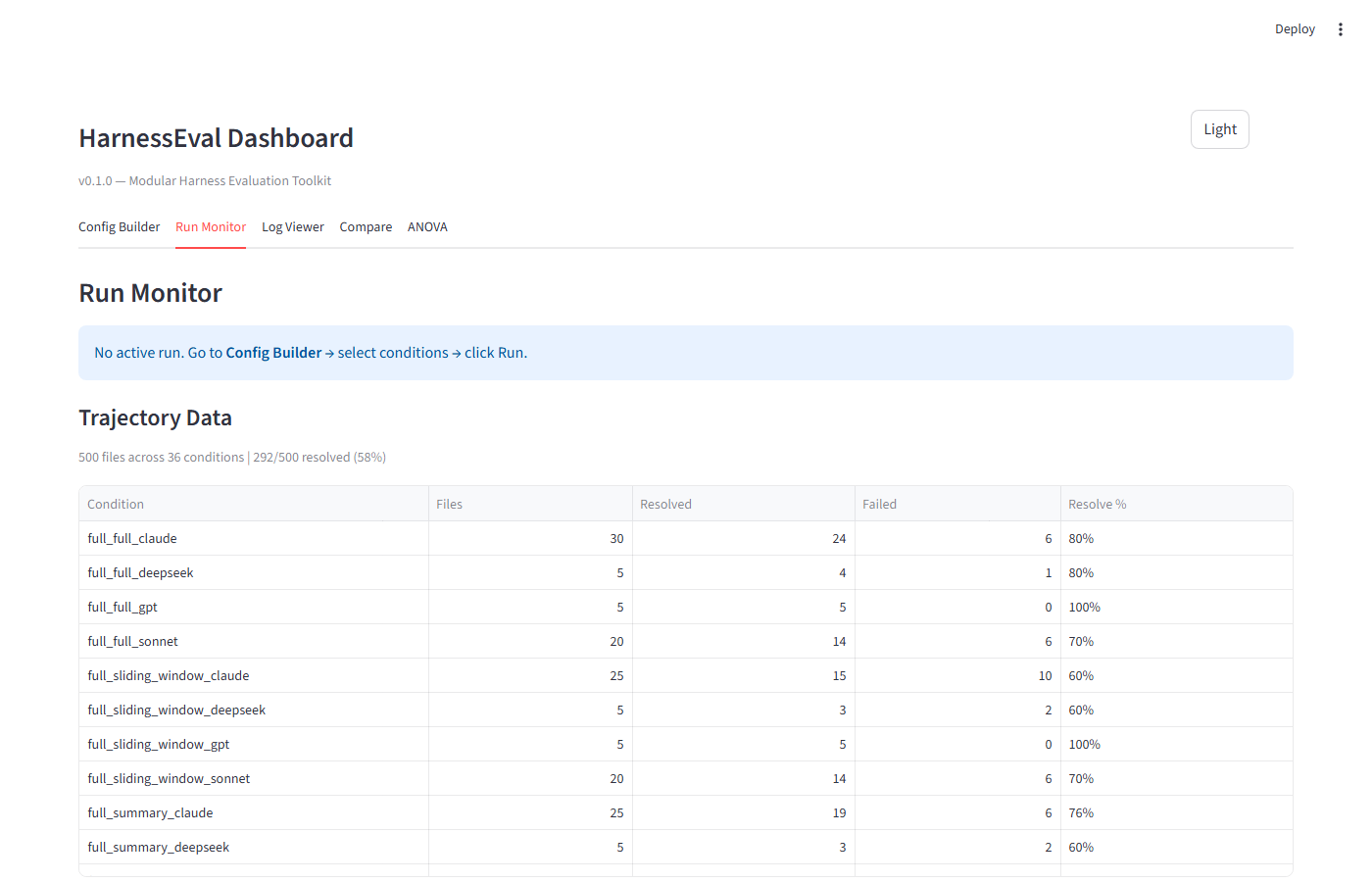
Tab 3: Log Viewer
Duyệt trajectory logs theo condition, xem turn-by-turn chi tiết với evaluation metrics.
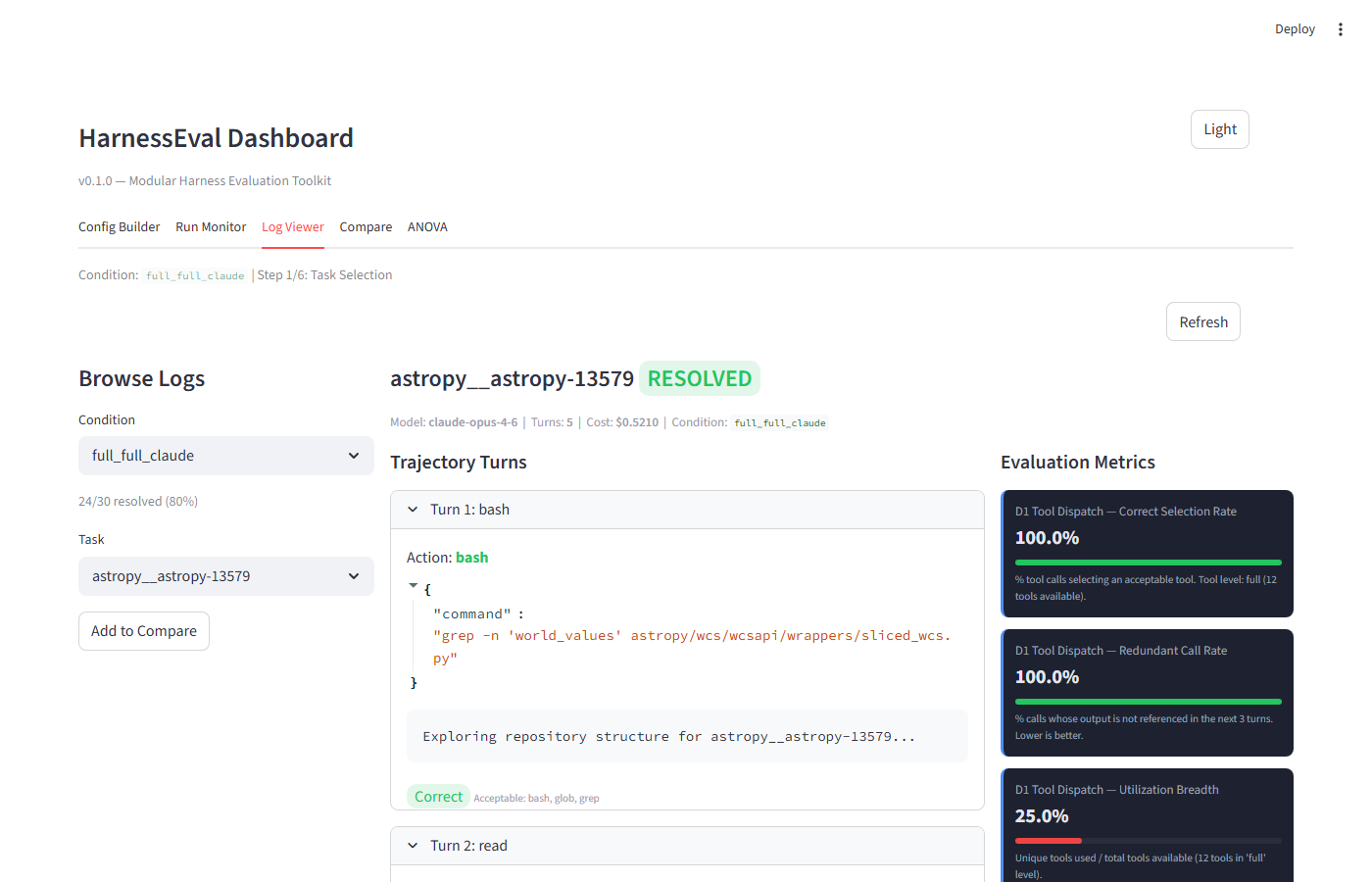
Mỗi turn hiển thị:
- Action type với color-coding (xanh dương = read/search, tím = edit/write, xanh lá = bash/test)
- Args dạng JSON
- Output truncated 500 chars
- Correctness badge (Correct/Wrong) so với acceptable tools
Metrics sidebar tính toán real-time M1.1, M1.2, M1.3, M2.2 cho mỗi log.
Tab 4: Compare
So sánh side-by-side giữa các conditions với metric-centric view.
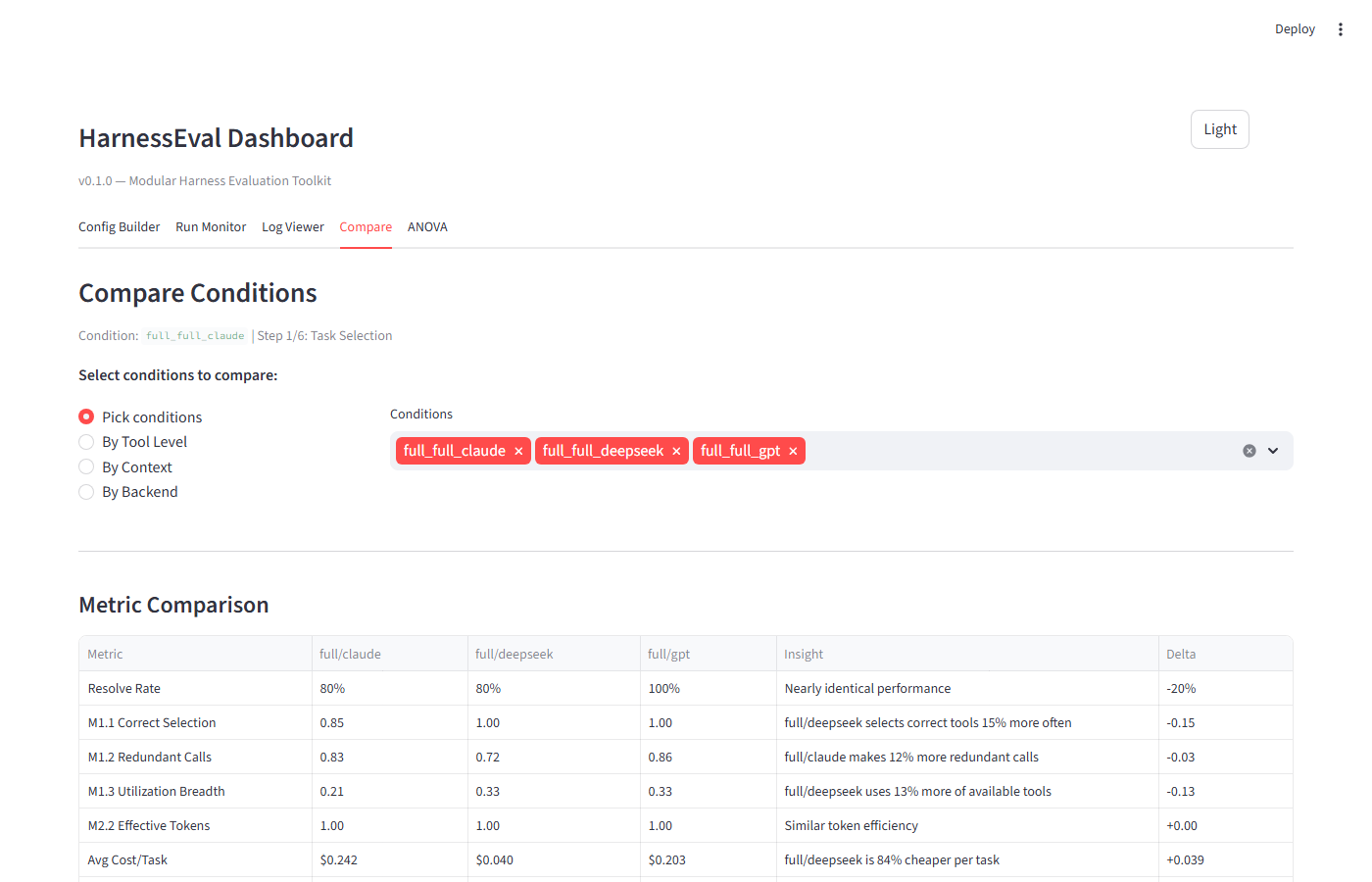
Features:
- Compare by: Pick conditions / By Tool Level / By Context / By Backend
- Metric comparison table với Delta và auto-generated Insights
- Grouped bar chart (Plotly) cho visual comparison
- Cross-Backend Portability metrics (M3.1, M3.2)
Tab 5: ANOVA Analysis
Three-way ANOVA đầy đủ với Bonferroni correction, Cohen’s d, Tukey HSD, và GLMM robustness check.
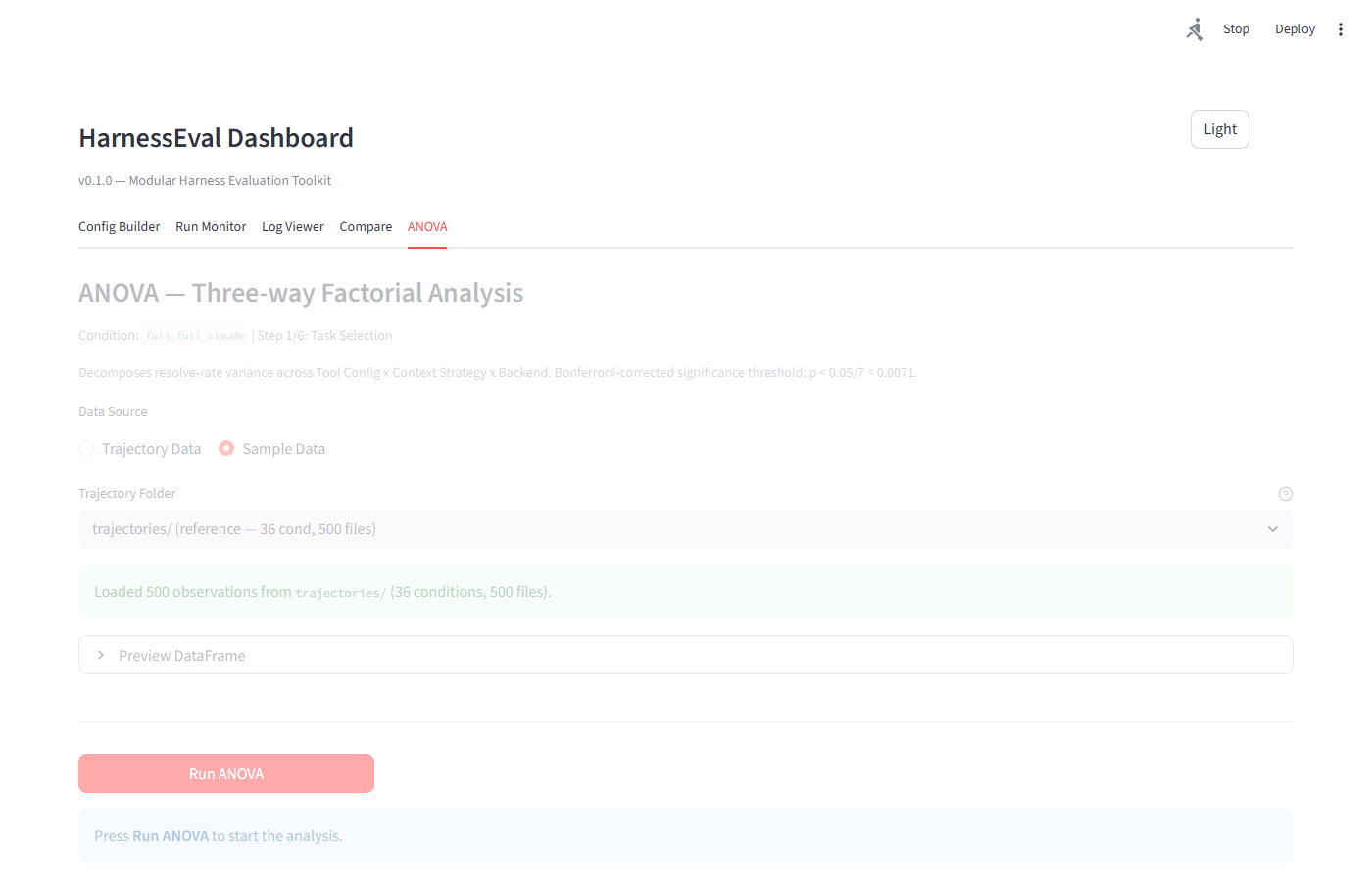
Tab ANOVA bao gồm:
- ANOVA Table với SS, df, MS, F, p-value, eta², significance markers
- Variance Pie Chart (Plotly) — % đóng góp mỗi factor
- Effect Size Bar Chart — so sánh eta² giữa các factors
- Hypothesis Evaluation — tự động kiểm tra H1-H4
- Pairwise Comparisons — Cohen’s d cho mọi cặp so sánh
- GLMM Robustness Check — mixed effects model với task_id random intercept
- Export — CSV download và paper-quality figures (300 DPI)
Pipeline End-to-End
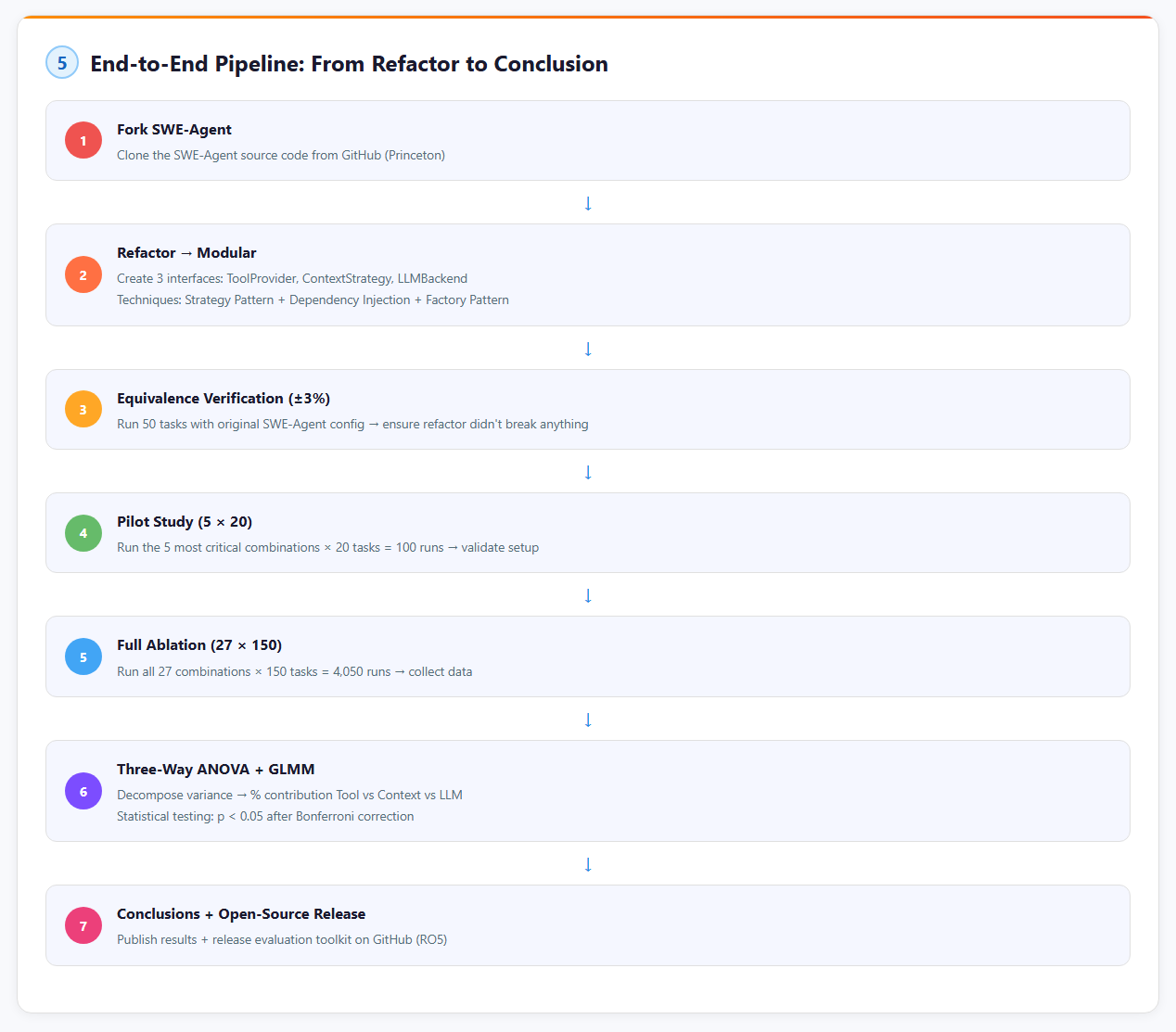
| Giai đoạn | Thời gian | Nội dung | Sản phẩm |
|---|---|---|---|
| GD1 | Tuần 1-6 | Thiết kế taxonomy + expert validation | Taxonomy v1.0 |
| GD1.5 | Tuần 7-8 | Pilot study (200 evals) | Pilot report |
| GD2 | Tuần 9-11 | Fork SWE-Agent + refactor modular | Modular harness v1.0 |
| GD3 | Tuần 12-18 | Full ablation (7,050 evals) | Raw data, ANOVA results |
| GD4 | Tuần 19-22 | Phân tích + guidelines + viết luận văn | Luận văn bản thảo |
| GD5 | Tuần 23-24 | Review, chỉnh sửa, phát hành toolkit | GitHub release |
Kỹ Thuật Implementation: Dependency Injection
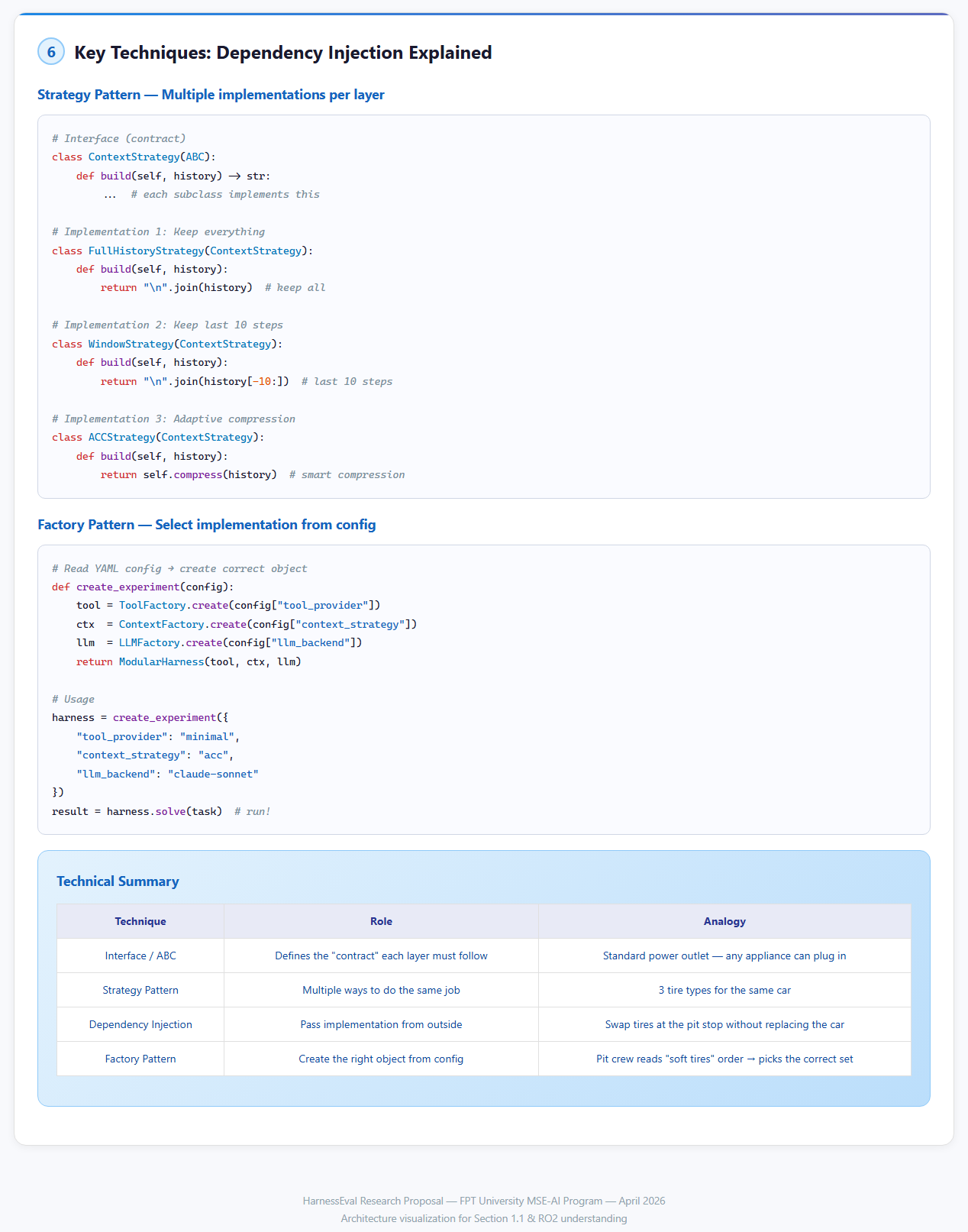
Code ví dụ — tạo harness từ YAML config:
def create_experiment(config: dict) -> Harness:
"""Factory: đọc YAML config → tạo đúng combination."""
tool = ToolFactory.create(config["tool_provider"])
ctx = ContextFactory.create(config["context_strategy"])
llm = LLMFactory.create(config["llm_backend"])
return ModularHarness(tool, ctx, llm)
# Usage
harness = create_experiment({
"tool_provider": "minimal",
"context_strategy": "sliding_window",
"llm_backend": "claude-sonnet-4",
})
result = harness.solve(task) # 4 dòng, swap bất kỳ layer nào4 design patterns được áp dụng:
| Technique | Role | Analogy |
|---|---|---|
| Interface/ABC | ”Contract” mỗi layer phải tuân thủ | Extension point — bất kỳ app nào cũng plug in |
| Strategy Pattern | Nhiều implementations cho cùng job | 3 tay đua cho cùng xe |
| Dependency Injection | Pass implementation lúc runtime | Pit crew swap lốp mà không cần redesign xe |
| Factory Pattern | Đọc YAML → tạo đúng object | ”Left lane” order → picks the correct set |
Ý Nghĩa Nghiên Cứu
Khoa học
- Đóng góp lý thuyết: Formalize cách tách rời harness quality khỏi LLM quality (ANOVA 2 chiều)
- Đóng góp thực nghiệm: Định lượng đóng góp từng component harness lần đầu tiên
- Toolkit: Framework đánh giá có thể tái sử dụng
Thực tiễn
- Developer: Biết nên ưu tiên cải thiện component nào
- Researcher: Framework chuẩn để so sánh harness mới
- Industry: Guidelines thiết kế harness dựa trên dữ liệu
Publishability
| Venue | Loại | Phù hợp |
|---|---|---|
| ICSE 2027 NIER | Conference (New Ideas) | Rất phù hợp |
| MSR 2027 | Conference | Phù hợp |
| LLM Agents Workshop (NeurIPS/ICML) | Workshop | Phù hợp |
| EMNLP Demo Track | Conference | Phù hợp |
Kết Luận
HarnessEval không phải là “thêm một benchmark nữa.” Đây là shift paradigm — từ đánh giá output sang đánh giá infrastructure. Khi biết tool dispatch đóng góp 35% và context management đóng góp 20% vào resolve rate, chúng ta có thể:
- Thiết kế harness tốt hơn — tập trung vào component quan trọng nhất
- So sánh công bằng — tách riêng khả năng LLM và chất lượng harness
- Tối ưu chi phí — biết khi nào nâng cấp LLM vs. cải thiện harness
Nếu bạn quan tâm đến nghiên cứu này, toolkit sẽ được open-source trên GitHub sau khi hoàn thành. Stay tuned.
Đề cương nghiên cứu cho chương trình Thạc sĩ Kỹ thuật Phần mềm (AI) — Đại học FPT. Đã qua phản biện hội đồng (v2).